
新增沿路对外投资,被投资公司为")
DeepSeek 发布了最新的参议恶果——原生稀薄着重力。这项时期有望大幅普及下一代鬼话语模子处理长文本的智力,同期还能兼顾遵守。

就在马斯克发布grok3,sam altman 还在踌躇要不要开源时,刚刚梁文锋手脚co-authors携deepseek参议团队丢出重磅参论说文恶果,DeepSeek 发布了最新的参议恶果——原生稀薄着重力(Native Sparse Attention, NSA)! 这项时期有望大幅普及下一代鬼话语模子处理长文本的智力,同期还能兼顾遵守,可谓是 LLM 范畴又一里程碑式的施展!

浅易来说,论文的中枢孝顺如下:
LLM 长文本智力再冲突!DeepSeek 发布原生稀薄着重力 NSA:硬件友好又高效,训推一体化!
空话未几说,咱们一王人来扒一扒这篇论文:
先了解一下论文的布景
连年来,咱们见证了长文本建模在 AI 范畴的热切性日益突显。无论是深度推理、代码库生成、如故多轮对话,都离不开模子对长序列信息的有用处聪敏力。像 OpenAI 的 o-series 模子、DeepSeek-R1、以及 Google Gemini 1.5 Pro 等,都展现了处理超长文本的宏大后劲。
然则,传统 Attention 机制的筹谋复杂度跟着序列长度的加多而呈平素级增长,这成为了制约 LLM 发展的关键瓶颈。筹谋资本繁华,延长成为问题, 如安在保证模子性能的同期,普及长文本处理的遵守,成为了亟待络续的贫乏
稀薄着重力应时而生,它被合计是普及遵守,同期保管模子智力的有但愿的方针。DeepSeek 的 NSA 时期恰是在这个方进取迈出了热切一步!
DeepSeek NSA:原生稀薄着重力,训推一体化,硬件友好
DeepSeek 无情的 NSA (Native Sparse Attention,原生稀薄着重力) 机制,玄机地将算法立异与硬件优化相伙同,旨在竣事高效的长文本建模。
NSA 的中枢亮点不错概述为以下两点:
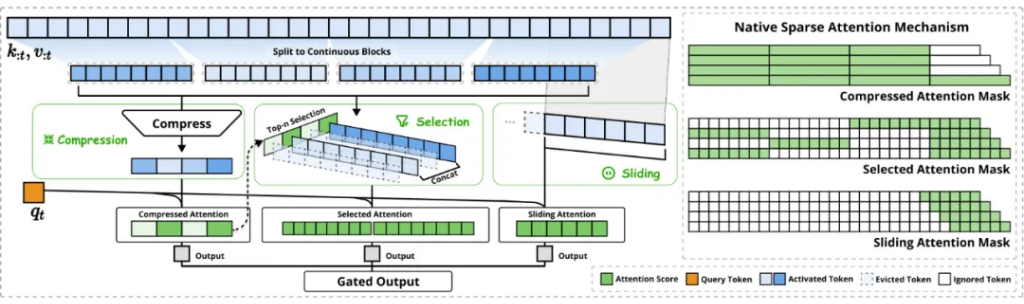
1.动态分层稀薄政策: NSA 接管了一种动态分层的稀薄政策,伙同了粗粒度的 Token 压缩 和 细粒度的 Token 遴荐。这种政策既能保证模子对全局高低文的感知,又能兼顾局部信息的精准性
2.两大关键立异:
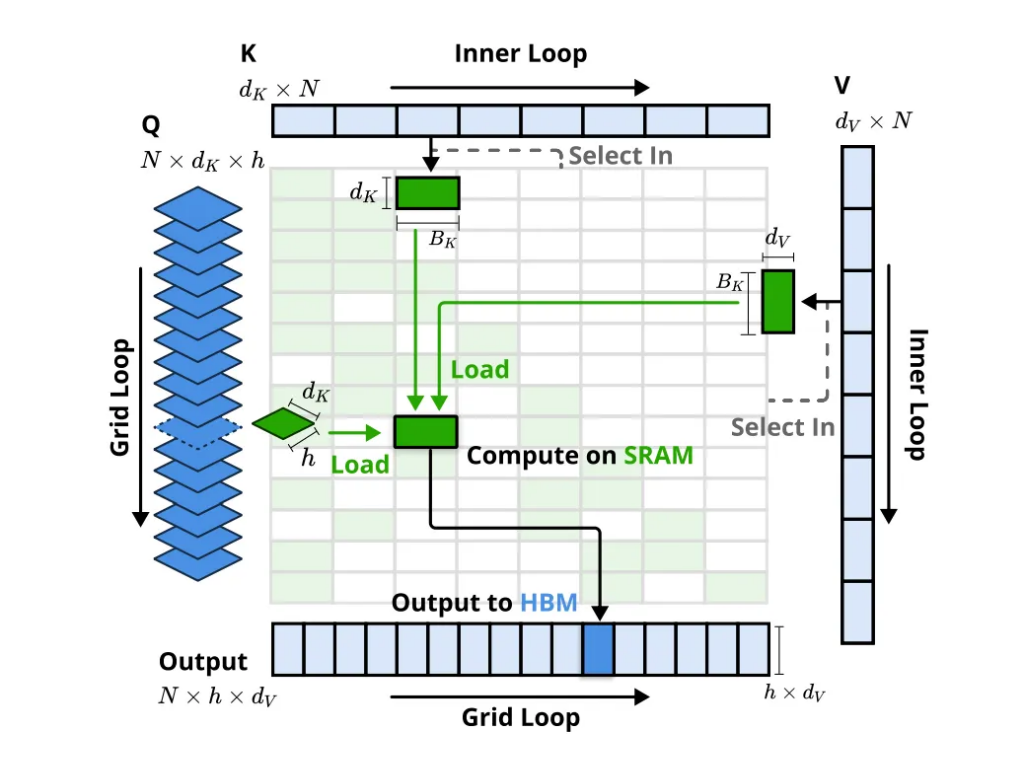
算术强度均衡的算法打算与硬件优化: NSA 通过小巧的算法打算,并针对当代硬件进行了竣事优化,显赫普及了筹谋速率
端到端可检修: NSA 支撑端到端检修,这意味着它不仅在推理阶段高效,还能减少预检修的筹谋量,同期不糟跶模子性能!
施行效果惊艳:性能不降反升,速率大幅普及!
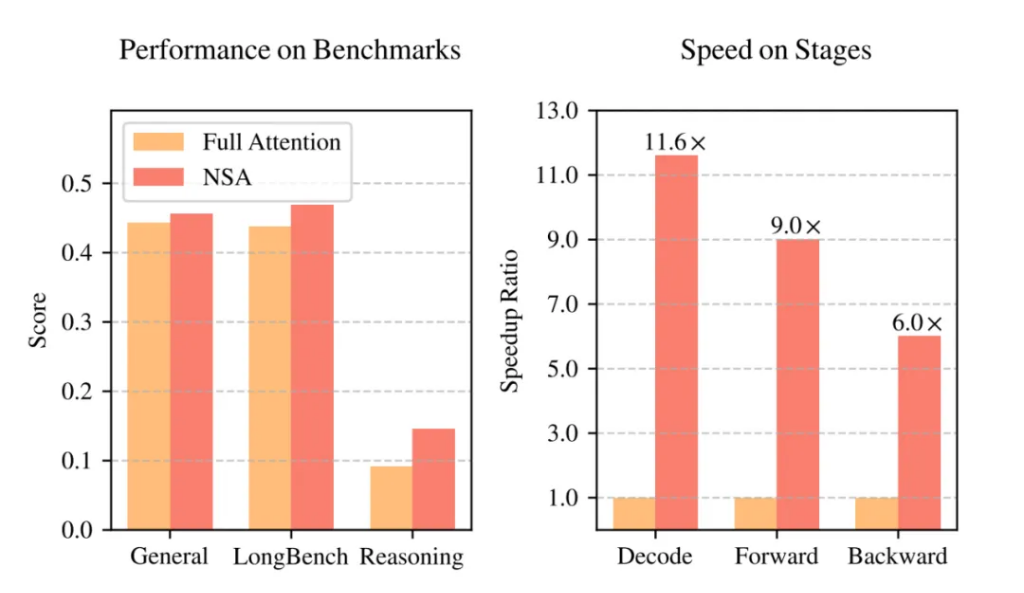
施行收尾令东谈主奋斗!如图 1 所示,在通用基准测试、长文本任务和提示推理方面,使用 NSA 预检修的模子性能不仅莫得着落,贵金属投资反而超越了 Full Attention 模子!
更热切的是,在处理 64k 长度的序列时,NSA 在解码、前向传播和反向传播等各个阶段都竣事了显赫的速率普及,最高可达 11.6 倍! 这充分讲明了 NSA 在模子生命周期各个阶段的遵守上风
现存稀薄着重力方法的局限性
论文也长远分析了现存稀薄着重力方法的局限性,主要体当前两个方面:
1.推理遵守的“假象”: 好多方法固然在表面上竣事了稀薄筹谋,但在本色推理延长方面普及有限。这主淌若因为:
• 阶段收尾的稀薄性: 举例,有些方法只在自记忆解码时应用稀薄性,但在预填充阶段仍然需要多数筹谋
• 与先进 Attention 架构的不兼容性: 一些稀薄着重力方法难以适配像 MQA 和 GQA 这么的当代高效解码架构,导致内存探询瓶颈也曾存在
2.可检修稀薄性的“外传”: 许多方法主要关切推理阶段的稀薄性,而忽略了检修阶段。这导致:
• 性能退化: 后验应用稀薄性可能导致模子偏离预检修的优化轨迹。
• 检修遵守需求: 长序列检修关于普及模子智力至关热切,但现存方法在检修遵守方面存在不及。
• 不行检修的组件: 一些方法引入了不行微的阻碍操作,抑遏了梯度传播,收尾了模子学习最好稀薄格式的智力。
• 反向传播遵守低下: 一些表面上可检修的方法,在本色检修中遵守低下,举例 Token 粒度的遴荐政策可能导致非连合的内存探询,影响硬件诈欺率。
NSA 的中枢组件:分层稀薄,逐层优化
为了克服上述局限性,NSA 架构接管了分层 Token 建模,并通过三个并行的着重力分支处理输入序列:
1. 压缩着重力 (Compressed Attention): 处理粗粒度的格式,通过压缩 Token 块来拿获全局信息。
2. 遴荐着重力 (Selected Attention): 处理热切的 Token 块,遴荐性地保留细粒度的信息。
3. 滑动窗口着重力 (Sliding Window Attention): 处理局部高低文信息。
这三个分支的输出通过一个门控机制进行团员。为了最大化遵守,NSA 还挑升打算了硬件优化的 Kernel
写在临了:
DeepSeek 的 NSA 时期为长文本建模带来了新的冲突。它不仅在性能上超越了传统的 Full Attention 模子,更在遵守方面竣事了显赫的普及,尤其是在长序列场景下。NSA 的 硬件友好打算 和 训推一体化特色,使其在本色应用中更具上风,有望加快下一代 LLM 在长文本处理范畴的应用落地。
这项参议无疑为稀薄着重力范畴带来了新的想路和方针。往时,咱们期待看到更多基于 NSA 时期的立异应用,共同激动 AI 时期的卓著!
临了不得不在强调一下,梁文锋不仅是deepseek ceo,很彰着他还在参议的最前沿参与参议,这是令我最震憾的,他不仅有管聪敏力,并且还确凿的懂AI,deepseek出路无量
各路网友都在喊,这才是确凿的OpenAI。
包袱裁剪:郭明煜