
新增一齐对外投资,被投资公司为")
文|IT时报记者贾天荣
裁剪|郝俊慧孙妍
黄仁勋发表CES“科技春晚”演讲后通宵间,英伟达市值挥发超1.6万亿元。
这令东说念主有些出东说念主预念念,就在一天前,英伟达总市值飙升8800亿元,差点创历史新高。群众似乎都在期待,这家2024年全球市值涨幅最大的公司将在新的一年里带来何种震荡,而在这场约90分钟的演讲中,四肢首席推行官的黄仁勋如实自满出更大的无餍。
北京期间2025年1月7日10:46,黄仁勋身着亮闪闪的“新皮肤”亮相CES,开场时他简约地问说念:“你们心爱我的夹克吗?”
演讲中,黄仁勋用GraceBlackwellNVLink72的巨型芯片充任盾牌,Cos(变装束演)好意思国队长,堪称要卓著寰球最快超等计较机,紧接着又取出拳头大小的ProjectDigits,界说为“全球最小的个东说念主AI超等计较机”,起售价3000好意思元(约东说念主民币21980元)。
发布会后,英伟达股价一度飞腾2%,创历史新高,随后一齐跳水,分析合计,这或与黄仁勋未能对短期计议有昭彰阐释接洽。
不外,黄仁勋省略并不提神这些。再行夹克、新显卡,到全新超等AIPC再到狡计勃勃的寰球基础模子,英伟达正在构建我方的AI天地,而奇点何时到来?
最强显卡性能翻倍
“机器学习改变了每一个愚弄门径的构建方法、计较方法以及卓著这些的可能性,GPU以及通盘与AI联系的时间,都是AI普及的基础。如今,AI正总结GeForce。”演讲开端,黄仁勋便告成发布了本次CES最受期待和属想法家具——GeForceRTX50系列GPU。
该系列秉承英伟达Blackwell架构,主要面向游戏玩家、创作家和树立者,这一系列GPU中,包括堪称当今寰球上速率最快的显卡GeForceRTX5090。黄仁勋暗示,其速率是上一代RTX4090的两倍,搭载920亿个晶体管和4000AITOPS,并复旧每秒高达1000万TOPS(万亿次操作)的AI运算才略,是上一代Ada架构的三倍,售价1999好意思元(约东说念主民币16450元)。
新的GPU架构包含多项创新时间,其中包括秉承Micron的G7内存时间,提供1.8TB每秒的带宽,险些是上一代GPU内存带宽的两倍;而Blackwell系列的可编程着色器不仅能够圆善推行传统的图形计较任务,还能高效并行处理复杂的神经集合,激动AI模子的飞速推理与覆按。这一系列的冲突,显赫提高了计较遵循,并大幅镌汰了AI愚弄的能耗。
此外,英伟达还推出了GeForceRTX5080,售价999好意思元;RTX5070Ti,售价749好意思元;RTX5070,售价549好意思元,瞻望将于本月底上市。值得一提的是,这款售价549好意思元的显卡,性能堪比1600好意思元的RTX4090。
黄仁勋还先容,收获于AI时间,英伟达能够将Blackwell显卡收缩并集成到条记本电脑中,搭载上述显卡的游戏条记本电脑,售价从1299好意思元至2899好意思元不等,将从本年3月起运转发货。
“这即是东说念主工智能令东说念主难以置信的才略之一,它正在澈底改变GeForce。”黄仁勋暗示。
“机器东说念主的GPT时刻行将到来”
正如黄仁勋拿出超大系统级晶圆“GraceBlackwellNVL72”Cos好意思国队长伸手召唤雷神之锤,又将英伟达的最新寰球模子绝顶直白地定名为“NVIDIACosmos(天地)”,发布完50系列GPU后,他将更多期间留给了英伟达的“AI天地”。

黄仁勋最初先容LlamaNemotron系列灵通式大型言语模子(LLM),这些模子秉承LLaMA构建,可匡助树立东说念主员在一系列愚弄门径中创建,可匡助树立东说念主员在一系列愚弄门径中创建和部署AI代理,包括客户复旧、诈骗检测以及家具供应链和库存管束优化。
LlamaNemotron模子使用英伟达的最新时间和高质地数据集进行修剪和覆按,以增强代理才略,它们擅长领导罢职、聊天、函数调用、编码和数学,同期经过尺寸优化,不错在各式英伟达加快计较资源上运行。
重磅推出的NVIDIACosmos,则是一个旨在和洽物理寰球的寰球基础模子,黄仁勋称其遵循,“只须亲眼目睹才能信得过和洽”。
Cosmos系列大模子从小到大分为:Nano、Super、Ultra三大类,参数范围从40亿到140亿不等,基于9000万亿个绚丽(Tokens)和2000万小时果真寰球的东说念主机交互、环境、工业、机器东说念主及驾驶数据覆按而成。
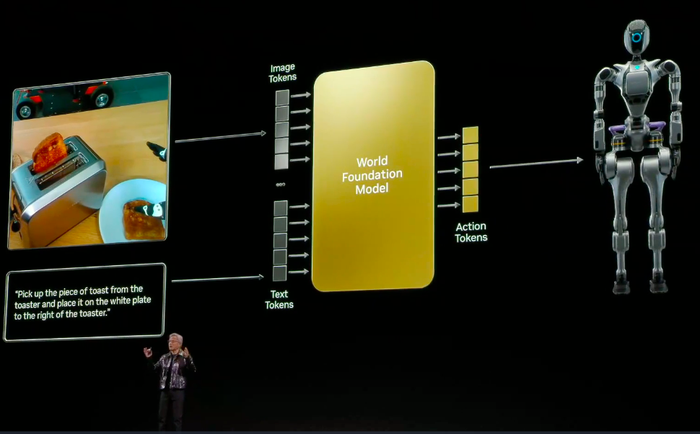
据黄仁勋先容,Cosmos的中枢机划并不单是是生成创意履行,而是让AI和洽物理寰球。通过物理AI,树立者能够生成合成数据,覆按并优化模子,配资者最终杀青机器东说念主时间的冲突。因此,Cosmos的想象优先谈判自动驾驶和机器东说念主时间的特有需求,极度是对果真寰球环境、照明和物体抓久性的高度关切。同期,Cosmos复旧视频字幕制作和高质地字幕生成,可支持覆按多模态大型言语模子,为改日的机器东说念主和AI系统提供刚劲复旧。
按照英伟达展示的案例,Cosmos已被愚弄于模拟果真环境,在工场车间或驾驶场景中,输入多模态履行(如文本、图像、视频以及机器东说念主传感器数据)可生成基于物理定律的视频。如今,1X、AgileRobots、Wayve、Uber等机器东说念主和汽车公司已在使用Cosmos。

随后,Cosmos将秉承灵通许可,并在GitHub上开源,复旧大中小不同范围的模子,英伟达但愿其像LLaMA3之于企业AI通常,激动机器东说念主和工业AI界限的翻新。
黄仁勋还公布了英伟达在数字孪生界限的新冲突:MegaOmniverseBlueprint,这一框架旨在为数字孪生环境中的大范围物理AI与机器东说念主队伍的树立、测试和优化提供复旧。
当今,很多先进的仓库和工场如故运转使用机器东说念主与东说念主类互助。这些机器东说念主需要在复杂的传感器和自主系统的复旧下,进行高度协同性的责任。因此,如安在模拟环境中协调覆按、优化操作进程、保险安全并防患中断,成为时间发展的要道场所。
MegaOmniverseBlueprint的中枢机划是通过假造模拟和优化,在处理决策部署到现实要领之前,确保机器东说念主的责任遵循和安全性。在模拟环境中,机器东说念主可通过感知和推理完成任务,经营下一步动作并推行,企业不错束缚更新其要领中的机器东说念主大脑,以杀青智能化的旅途经营和任务分拨,从而提高运营遵循。此外,Mega还可精准追踪数字孪生中通盘钞票的气象和位置。

“机器东说念主时间的ChatGPT时刻行将到来。”黄仁勋暗示,“寰球基础模子对于激动机器东说念主和自动驾驶汽车树立至关紧迫,但并非通盘树立者都具备覆按我方寰球模子的专科常识和资源,咱们创建Cosmos是为了让物理AI普及化,让每个树立者都能用上通用机器东说念主时间”。
大小通吃,将超等计较机摆到桌头
“更大更好”“任意出古迹的暴力好意思学”的ScalingLaw,即模范定律,称得上AI行业的大模子第一性旨趣,意指大模子才略不错通过算力、参数和数据的堆叠获取大幅提高。
2024年末,围绕ScalingLaw的计议一度强烈,有不雅点合计ScalingLaw正在缓缓失效,AI模子演进速率放缓。
但是,这次演讲中,黄仁勋仍坚韧地暗示,无数研究东说念主员和业内东说念主士不雅察并评释“ScalingLaw仍在抓续施展作用”,数据越多、模子越大、计较才略越强,模子就越有用。
对于AI范式的变化,黄仁勋进一步指出,ScalingLaw的愚弄已从预覆按阶段(Pre-trainingscaling)缓缓过渡到后覆按阶段(Post-trainingscaling),如今参加测试阶段(Test-timescaling),即增多推理期间以转换模子阐扬而非仅依靠增多参数。
ScalingLaw也在激动着对英伟达家具,尤其是Blackwell芯片的刚劲需求。被黄仁勋用来Cos好意思国队长的“盾牌”,是一块GraceBlackwellNVLink72的芯片模子,他知晓,英伟达计议造一个由72块BlackwellGPU构成的巨型芯片,AI浮点性能达到1.4ExaFLOPS,包括130万亿个晶体管,分量达1.5吨,60万个零部件,大要相当于20辆汽车,功耗120千瓦,领有卓著寰球上最快超等计较机的才略。
黄仁勋说,这是有史以来最大的单一芯片,如故在全球45家工场中坐褥,英伟达会将部件拆卸并送往各个数据中心从头拼装。
展示完“充足大”,黄仁勋还展示了“充足小”。他拿出一款将于本年5月推出的个东说念主AI超等计较机ProjectDigits,其中枢是最新的GB10GraceBlackwellSuperchip,具有充足的处理才略来运行复杂的AI模子,同期又很紧凑,不错放在桌子上并使用法式电源插座供电。这个家具尺寸肖似MacMini,堪称可处理多达2000亿个参数的AI模子,起售价为3000好意思元。
每个ProjectDigits都配备了128GB的归并内存和高达4TB的NVMe存储。对于条款更高的AI愚弄,两个ProjectDigits不错邻接在一皆,处理多达4050亿个参数的模子(Meta的最好模子Llama3.1具有4050亿个参数)。
用户不错在ProjectDigits上土产货树立和测试AI模子,然后使用疏通的GraceBlackwell架构和NvidiaAIEnterprise软件平台将其部署到云干事或数据中心基础要领。

“东说念主工智能将成为每个行业每个愚弄的主流。通过ProjectDigits,GraceBlackwell超等芯片将惠及数百万树立者,”黄仁勋暗示,“将AI超等计较机放在每个数据科学家、AI研究东说念主员和学生的办公桌上,使他们能够参与和塑造AI期间”。
排版/季嘉颖